
L’infection par le coronavirus 2 du syndrome respiratoire aigu sévère (SRAS-CoV-2) est généralement diagnostiquée par PCR de transcription inverse ou RT-PCR, mais cette méthode est loin d’être parfaite. Selon une étude, la RT-PCR a une sensibilité réelle d’environ 70 % et une spécificité de 95 %, bien que des résultats négatifs n’indiquent pas nécessairement un diagnostic négatif.
De plus, une analyse systématique des données individuelles des patients a révélé que la RT-PCR manque fréquemment le SRAS‑CoV‑2 et qu’un échantillonnage précoce peut réduire les faux négatifs. Par conséquent, ces tests sont souvent plus utiles pour statuer sur le COVID-19 que pour l’exclure.
Dans les cas où un test RT-PCR est négatif, mais qu’un patient présente des symptômes de COVID-19, des tests supplémentaires peuvent être nécessaires.
Compte tenu de l’augmentation exponentielle du nombre de cas de COVID-19 dans le monde et de la pression croissante sur les ressources médicales, les méthodes de diagnostic automatisées peuvent réduire efficacement la charge des radiologues déclarants.
Les images CT (tomodensitométrie) sont composées de plusieurs tranches, créant un effet tridimensionnel (3D). Une limitation fondamentale des mesures précédemment signalées utilisant des méthodes basées sur l’image CT-scan est la nécessité d’avoir le même nombre de tranches que leurs entrées, ce qui n’est pas viable dans différents volumes CT.
Trois limitations courantes de ces modèles sont le manque de méthodes suffisamment documentées pour la reproductibilité, le non-respect des protocoles réglementaires standard pour le développement de modèles d’apprentissage en profondeur et l’absence d’études de validation externes pour valider le programme dans la population réelle.
Les chercheurs ont cherché à résoudre les problèmes mentionnés ci-dessus dans une étude récente publiée sur le medRxiv* serveur de préimpression.
À l’aide de lignes directrices sur les meilleures pratiques, ils ont développé un modèle d’apprentissage en profondeur à effets mixtes pour classer avec précision les images comme saines ou COVID-19. En outre, un objectif secondaire était de démontrer comment les algorithmes d’apprentissage en profondeur pouvaient satisfaire aux directives actuelles des meilleures pratiques pour créer des modèles reproductibles et moins biaisés.
Détails de l’étude
Le modèle à effets mixtes proposé a été développé en utilisant rétrospectivement les données de la Russie et de la Chine. Les données en Russie ont été recueillies entre le 1er mars 2020 et le 25 avril 2020. Le Consortium chinois d’enquête sur les images CT thoraciques (CC-CCII) a fourni des données entre le 25 janvier 2020 et le 27 mars 2020. L’étude a porté sur les données de 1 110 et 796 patients atteints de COVID-19 ou de volumes CT sains de Russie et de Chine, respectivement.
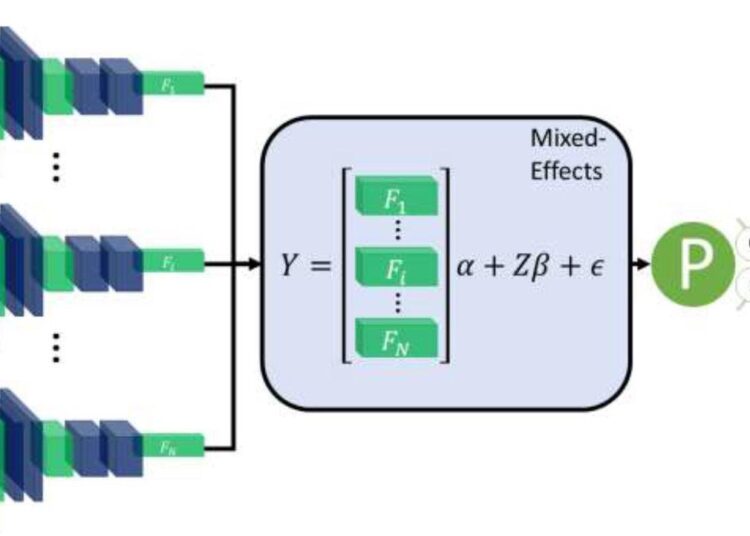
Schéma du cadre général. Vingt coupes sont choisies dans un volume CT. Chaque tranche est introduite dans un CNN avec des poids partagés, qui génère un vecteur caractéristique de longueur 2048 pour chaque image. Les vecteurs de caractéristiques forment une matrice d’effets fixes de 20 par 2048, X, pour le modèle GMM avec une matrice d’effets aléatoires, Z, constituée d’une matrice d’identité. Un modèle à effets mixtes est utilisé pour modéliser la relation entre les tranches. Enfin, une couche entièrement connectée et une activation sigmoïde renvoient une probabilité de diagnostic.
La méthode proposée utilise un extracteur de caractéristiques et un modèle linéaire généralisé à effets mixtes (GLMM) en deux étapes, utilisant la rétropropagation. Les modèles à effets mixtes sont des modèles statistiques constitués d’une partie à effets fixes et d’une partie à effets aléatoires. La partie à effets fixes est utilisée pour modéliser la relation au sein de la tranche CT, et la partie à effets aléatoires modélise ensuite la corrélation spatiale entre les tranches CT au sein de la même image.
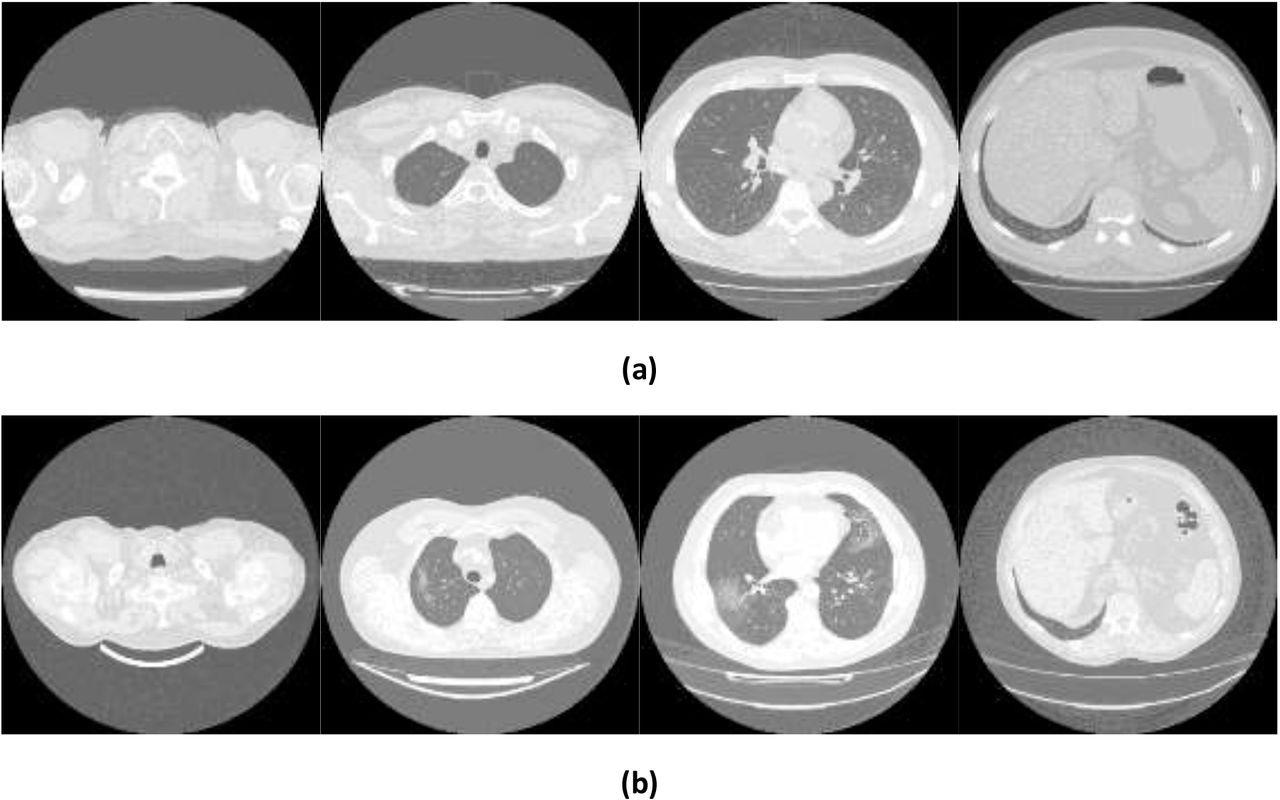
Exemples d’images montrant (a) des poumons sains et (b) COVID-19 tirés de l’ensemble de données Mosmed.
Tout d’abord, une série de tranches CT formant un volume CT a été introduite dans le modèle. Cette étape a été suivie d’une couche à effets mixtes qui concatène les vecteurs de caractéristiques en un seul vecteur. Enfin, une couche entièrement connectée suivie d’une activation sigmoïde a donné une probabilité de COVID-19 pour l’ensemble du volume. Les effets mixtes et la couche entièrement connectée avec activation sigmoïde étaient analogues à un GLMM linéaire dans les statistiques traditionnelles.
Pour l’extracteur de caractéristiques, les chercheurs ont utilisé InceptionV3, un réseau neuronal convoluté (CNN). Après avoir sélectionné le réseau de neurones, les chercheurs ont utilisé une couche de regroupement moyenne globale pour réduire chaque image à un vecteur de caractéristiques pour chaque tranche, avec un abandon de 0,6 pour améliorer la généralisabilité aux images invisibles. Les vecteurs de caractéristiques ont ensuite été transformés en une matrice 20 × 2048. La nouveauté de ce processus résidait dans le fait que les chercheurs utilisaient une couche à effets mixtes auparavant utilisée uniquement dans les calculs statistiques rigoureux pour modéliser la relation entre les tranches.
Les chercheurs ont utilisé un ensemble de données de validation interne pour former le modèle proposé. Le modèle a montré un AUROC (aire sous la courbe de fonctionnement du récepteur) de 0,936 (IC à 95 % : 0,910, 0,961). En utilisant un seuil optimal de 0,740, la sensibilité, la spécificité, la valeur prédictive négative (VPN) et la valeur prédictive positive (VPP) étaient de 0,807 (0,761, 0,853), 0,953 (0,908, 0,853), 0,983 (0,966, 1,0) , et 0,596 (0,513, 0,678), respectivement.
Lors de la validation externe du modèle, il a atteint un AUROC de 0,930 (0,914, 0,947). En utilisant un seuil optimal de 0,878, la sensibilité, la spécificité, la VPN et la VPP étaient respectivement de 0,758 (0,722, 0,793), 0,963 (0,939, 0,987), 0,979 (0,965, 0,993) et 0,636 (0,587, 0,685). .
Lorsque 20 % des images CT-scan manquaient dans l’ensemble de données de validation, il y avait une réduction statistiquement significative des performances prédictives du modèle. Bien que, même à 50 % de données manquantes, le modèle a continué à fonctionner relativement bien, avec un AUROC de 0,890 (IC à 95 % : 0,868, 0,912), soulignant sa robustesse.
Implication
Cette étude est un autre indicateur de l’exploitation de la puissance de l’apprentissage en profondeur pour le dépistage et la surveillance du COVID-19 dans un cadre clinique. Cependant, la validation dans le cadre prévu est essentielle et les modèles ne doivent pas être adoptés sans cela. Cette étude a également souligné l’importance de la validation externe dans le développement d’un modèle robuste pour la prédiction des maladies.
*Avis important
medRxiv publie des rapports scientifiques préliminaires qui ne sont pas évalués par des pairs et, par conséquent, ne doivent pas être considérés comme concluants, guider la pratique clinique/les comportements liés à la santé, ou traités comme des informations établies.
















