
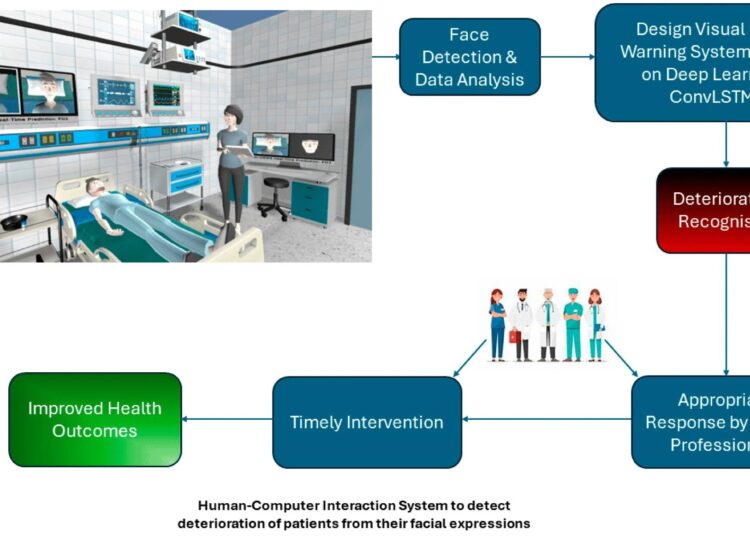
Dans une étude récente publiée dans la revue Informatiqueles chercheurs ont étudié l’utilisation de méthodes avancées d’apprentissage automatique pour reconnaître les expressions faciales comme indicateurs de détérioration de la santé chez les patients.
Leurs résultats indiquent que le modèle de mémoire à long terme convolutionnelle (ConvLSTM) développé peut prédire avec précision les risques pour la santé avec une précision impressionnante de 99,89 %, ce qui pourrait améliorer la détection précoce et les résultats pour les patients en milieu hospitalier.
Étude : Système d'alerte précoce visuelle basé sur l'IA
Sommaire
Arrière-plan
Les expressions faciales sont essentielles à la communication humaine, car elles transmettent des émotions et des signaux non verbaux dans différentes cultures. Charles Darwin a été le premier à explorer l'idée selon laquelle les mouvements du visage révèlent des émotions, et des recherches ultérieures menées par Ekman et d'autres ont permis d'identifier des expressions faciales universelles liées à des émotions spécifiques.
Le système de codage des expressions faciales (FACS), développé par Ekman et Friesen, est devenu un outil essentiel pour étudier ces expressions en analysant les mouvements musculaires impliqués. Au fil du temps, l'étude de la reconnaissance des expressions faciales (FER) s'est étendue à des domaines tels que la psychologie, la vision par ordinateur et les soins de santé.
Différents modèles et bases de données ont été créés pour améliorer la détection automatique des expressions faciales, notamment en milieu clinique. Parmi les avancées récentes, on peut citer l’utilisation de réseaux neuronaux convolutionnels (CNN) et d’autres techniques d’apprentissage automatique pour reconnaître les expressions faciales et prédire les problèmes de santé.
Ces développements sont particulièrement précieux dans le domaine des soins de santé, où la reconnaissance précise d’émotions telles que la douleur, la tristesse et la peur peut aider à la détection précoce de la détérioration de l’état du patient, améliorant ainsi les soins et les résultats.
À propos de l'étude
L'étude a utilisé une méthodologie systématique pour développer et évaluer un modèle de mémoire à long terme convolutionnelle (ConvLSTM) pour reconnaître les expressions faciales, en particulier celles indiquant une détérioration de l'état du patient. Le processus comportait trois phases clés : la génération de l'ensemble de données, le prétraitement des données et la mise en œuvre du modèle ConvLSTM.
Tout d’abord, un ensemble de données d’avatars animés en trois dimensions affichant diverses expressions faciales a été généré à l’aide d’outils avancés. Ces avatars ont été conçus pour imiter les visages de vrais humains avec diverses caractéristiques telles que l’âge, l’origine ethnique et les traits du visage.
Chaque avatar a réalisé des expressions spécifiques liées à la détérioration de la santé, ce qui a donné lieu à 125 clips vidéo. Le modèle de mouvement du premier ordre (FOMM) a ensuite été utilisé pour transférer ces expressions vers des images statiques à partir d'une base de données open source, élargissant ainsi l'ensemble de données à 176 clips vidéo.
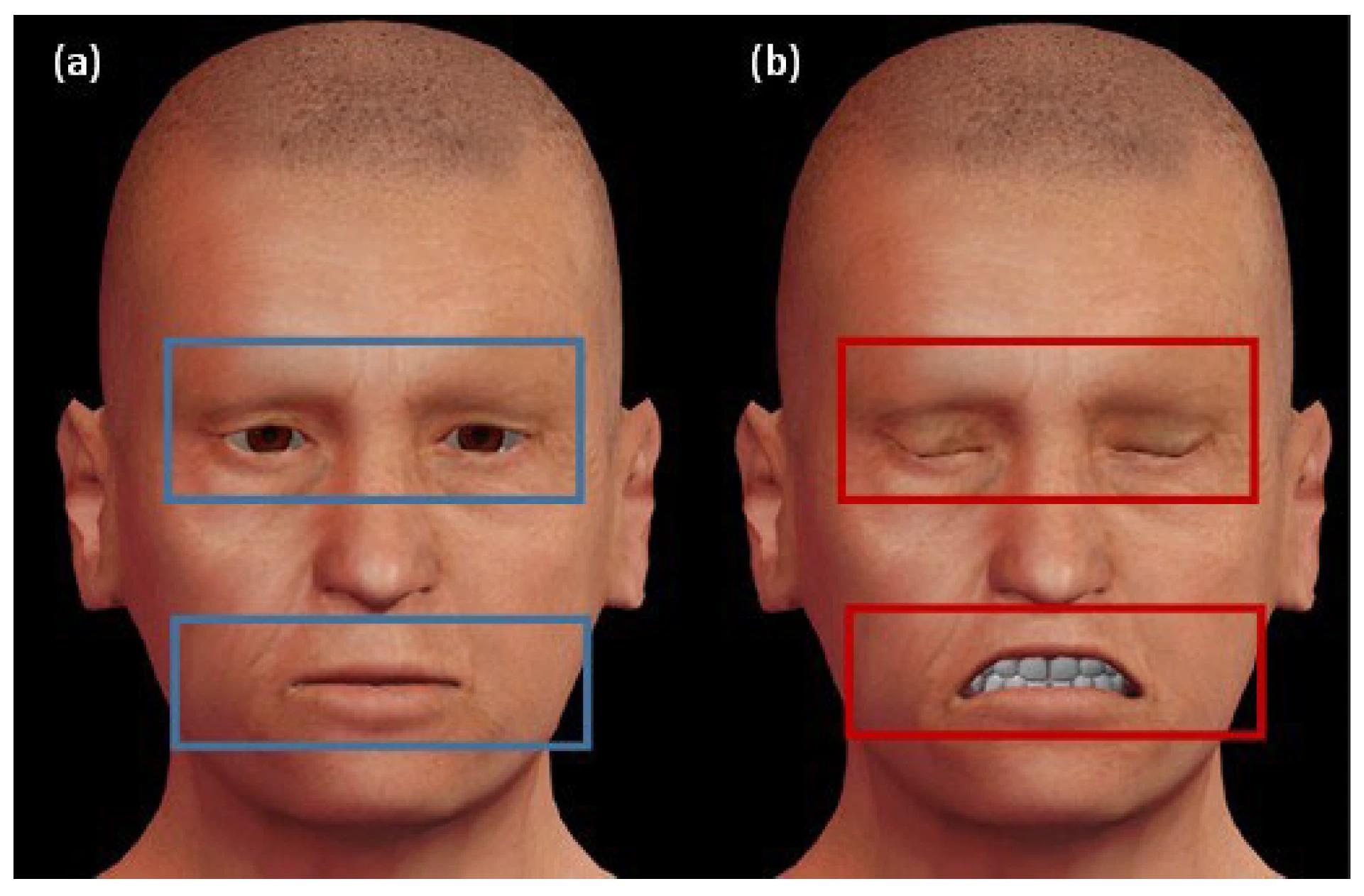 Zones d'expression faciale qui révèlent si le patient est en détérioration ou non.un) L'avatar de gauche exprime une expression neutre, qui est délimitée par les rectangles bleus.b) L'avatar de droite révèle l'état de détérioration au stade final, qui est délimité par les rectangles rouges.
Zones d'expression faciale qui révèlent si le patient est en détérioration ou non.un) L'avatar de gauche exprime une expression neutre, qui est délimitée par les rectangles bleus.b) L'avatar de droite révèle l'état de détérioration au stade final, qui est délimité par les rectangles rouges.
Ensuite, l'ensemble de données a subi un prétraitement rigoureux, qui comprenait la détection des visages pour isoler et se concentrer sur les régions du visage. L'ensemble de données a été divisé en ensembles d'entraînement (85 %) et de test (15 %) et des techniques de suréchantillonnage ont été appliquées pour équilibrer les données d'entraînement.
Enfin, le modèle ConvLSTM, qui intègre des couches convolutionnelles avec des cellules LSTM, a été proposé et implémenté pour capturer les dépendances spatiales et temporelles dans les séquences vidéo, permettant une prédiction précise des expressions faciales au fil du temps.
 Images d'échantillon vidéo après avoir utilisé FOMM pour transférer les expressions faciales des avatars vers des images faciales réelles.
Images d'échantillon vidéo après avoir utilisé FOMM pour transférer les expressions faciales des avatars vers des images faciales réelles.
Résultats
L’étude a introduit un modèle conçu pour détecter des expressions faciales spécifiques associées à la détérioration de l’état des patients. Ce modèle a été formé et testé sur un ensemble de données généré à partir d’avatars, qui simulaient cinq classes d’expressions faciales. Ces expressions ont été conçues pour représenter une gamme diversifiée de repères faciaux, de tons de peau et d’ethnies, imitant ainsi les patients à risque de déclin clinique.
Les performances du modèle ont été évaluées à l'aide de plusieurs indicateurs clés. Il a atteint une grande précision (99,8 %), une grande exactitude (99,8 %) et un rappel (99,8 %), démontrant ainsi l'efficacité du modèle à identifier correctement les expressions faciales pertinentes.
La précision mesure la fréquence à laquelle le modèle prédit correctement les expressions, tandis que la précision et le rappel se concentrent sur la capacité du modèle à identifier correctement les expressions positives sans fausses alarmes.
Le modèle ConvLSTM s’est avéré supérieur aux autres méthodes utilisées. Il a excellé dans la reconnaissance de modèles d’expressions faciales au fil du temps, ce qui est essentiel pour évaluer avec précision l’état des patients.
Une analyse plus approfondie a inclus l'utilisation d'une matrice de confusion et de courbes ROC (Receiver Operating Characteristic) pour évaluer les performances du modèle, en particulier dans la gestion des ensembles de données déséquilibrés. Le modèle a également été testé sur des données non vues, montrant une précision constante dans différentes classes d'expressions.
Ces résultats suggèrent que le modèle ConvLSTM est très efficace pour prédire la détérioration des patients en fonction de leurs expressions faciales, bien que les auteurs reconnaissent la nécessité d’études futures impliquant des données de patients réels pour valider ces résultats dans des scénarios pratiques.
Conclusions
L’étude a développé un modèle basé sur l’apprentissage profond utilisant l’architecture ConvLSTM pour détecter les expressions faciales indiquant une détérioration de l’état du patient, atteignant une précision élevée de 99,89 %.
Le modèle a été formé sur un ensemble de données synthétiques représentant cinq expressions faciales spécifiques associées à un risque de détérioration. Le système a montré des résultats prometteurs, soulignant le potentiel de l'utilisation de techniques avancées de vision par ordinateur et d'apprentissage automatique pour la détection précoce du déclin des patients.
Cependant, l'étude présente une limite importante : elle s'appuie sur des données synthétiques plutôt que sur des données réelles de patients. Des préoccupations éthiques ont empêché la collecte de données réelles sur les patients, en particulier dans les unités de soins intensifs et de réanimation.
Les chercheurs ont conclu en soulignant la nécessité de travaux futurs impliquant des données du monde réel pour valider davantage le modèle et l’intégrer à d’autres systèmes d’évaluation médicale afin d’améliorer les résultats des patients.
















